
Hui Wang, Dan Guo, Xiansheng Hua, and Meng Wang
ACM International Conference on Multimedia (ACM MM), 2021
[Paper] [BibTex]
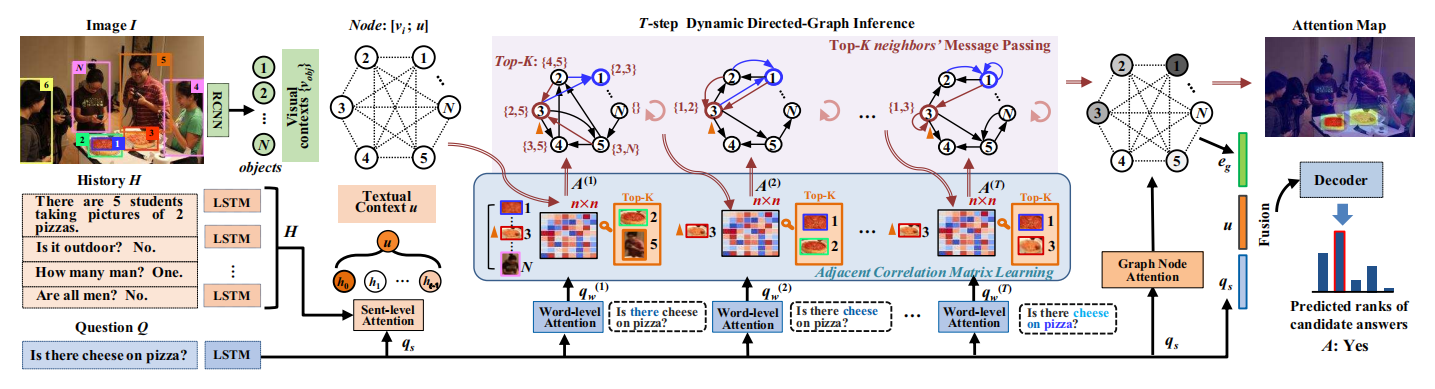
Dan Guo, Hui Wang, and Meng Wang
IEEE Transactions on Pattern Analysis and Machine Intelligence(TPAMI), 2021
[Paper] [BibTex]
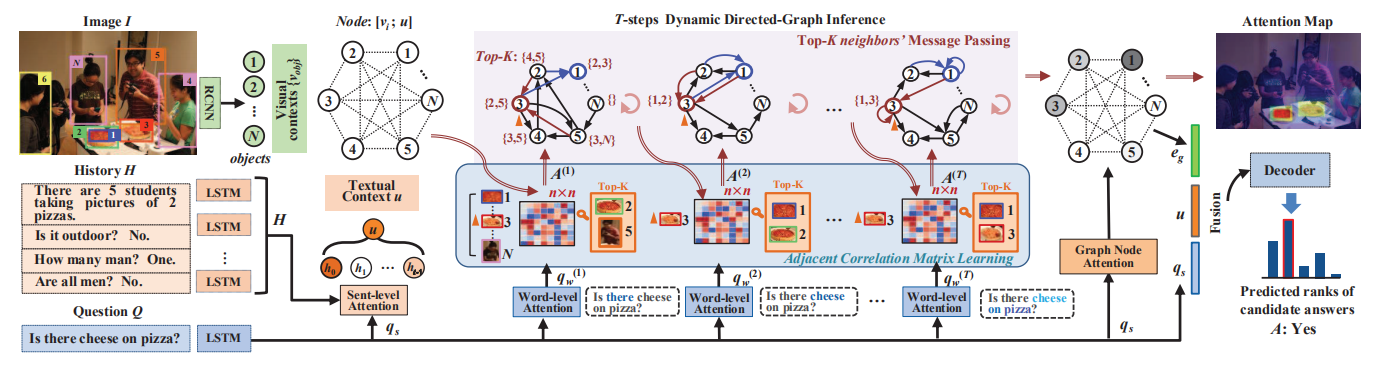
Dan Guo, Hui Wang, Hanwang Zhang, Zhengjun Zha, and Meng Wang
Conference on Computer Vision and Pattern Recognition (CVPR), 2020
[Paper] [BibTex]
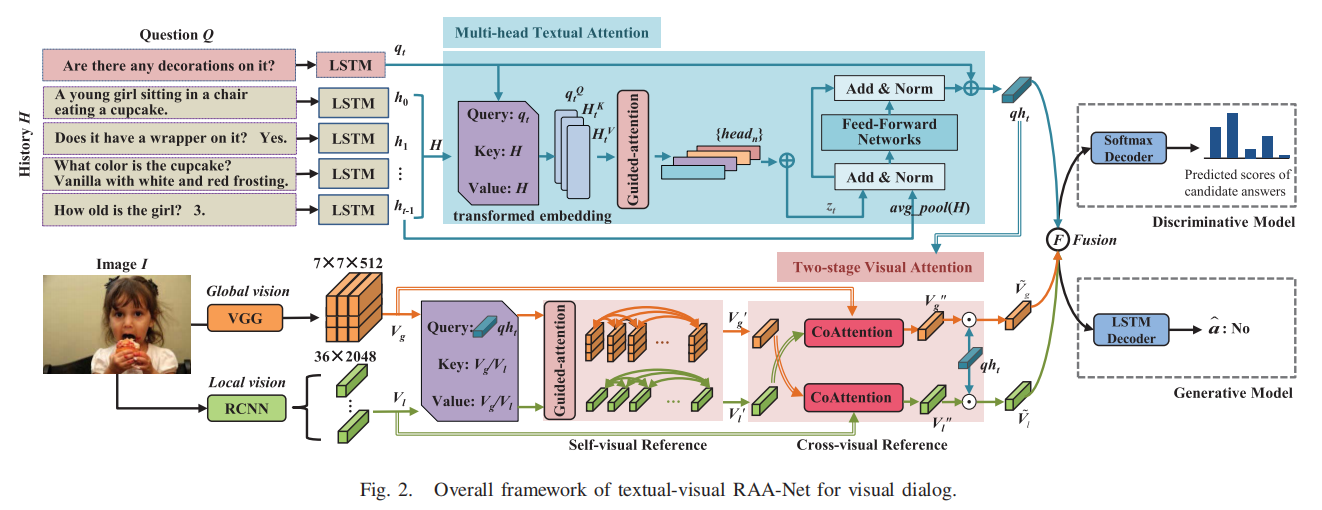
Dan Guo, Hui Wang, Shuhui Wang, and Meng Wang
IEEE Transactions on Image Processing (TIP), 2020
[Paper] [BibTex]
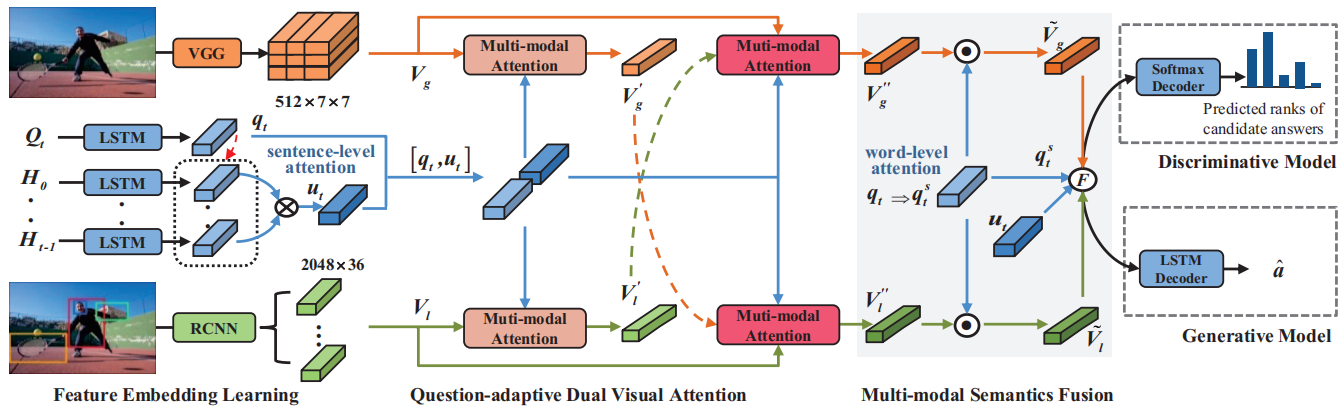
Dan Guo, Hui Wang, and Meng Wang
International Joint Conference on Artificial Intelligence (IJCAI), 2019
[Paper] [BibTex]
