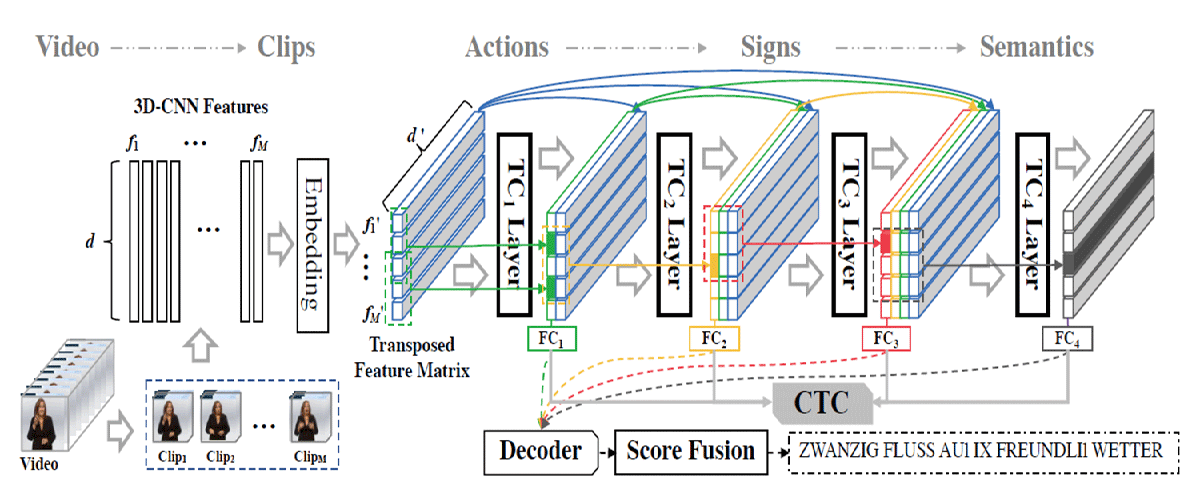
本部分涵盖与手语识别相关的研究,主要是连续手语翻译(CSLT)。为了提高离散手语词的识别准确性,一些早期的工作设计了一种自适应隐马尔可夫模型(HMM)框架。 这些方法可以充分探索隐藏手语状态之间的内在属性和互补关系。 CSLT面临着混合语义学习带来的挑战,其中包括视觉表示、手语语言学和文本语法的顺序变化······ [详细]

本部分涵盖与跨媒体视觉推理相关的研究,主要包括基于图像/视频的问答和对话生成。 [Details]
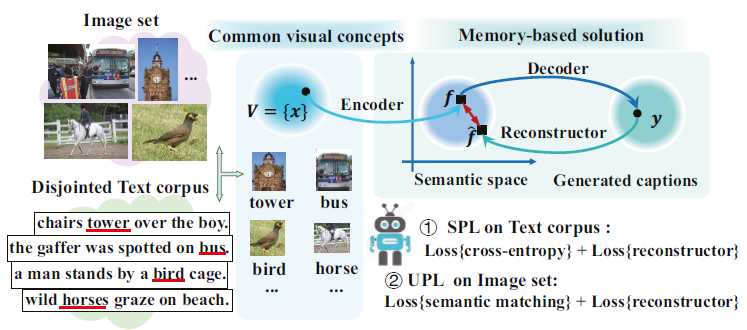
本部分涵盖与视觉描述生成相关的研究,主要是指根据图像/视频的内容自动生成文本的描述,最新的工作包括跨语言的视觉字幕生成和情感视频描述等。 [Details]

本部分涵盖与视觉内容理解相关的研究,包括基于图像的人群基数、基于图像的视觉对象定位、文本引导下的视频动作定位等。 [Details]