Visual Understanding Team
Hefei University of Technology (HFUT)
Laboratory for Multimedia Computing (LMC)
Visit the Chinese Version [中文]
Introduction
Visual Understanding Team targets on understanding, generating, and transforming multimedia content via computer vision and natural language processing techniques. We are working on sign language translation, image/video captioning, visual dialogue, video grouding and VQA. We have published 20+ journal articles and conference papers, including IEEE TPAMI, IEEE TIP, IEEE TMM, ACM TOMCCAP, CVPR, AAAI, IJCAI, ACM MM, etc.
News
Jun. 2022: One paper is accepted to ECCV 2022.
Jun. 2022: One paper is accepted to ACM MM 2022.
Aug. 2021: One paper is accepted to ACM MM 2021.
Dec. 2020: One paper is accepted to AAAI 2021.
Researches
|
|
|
|
Sign Language Translation
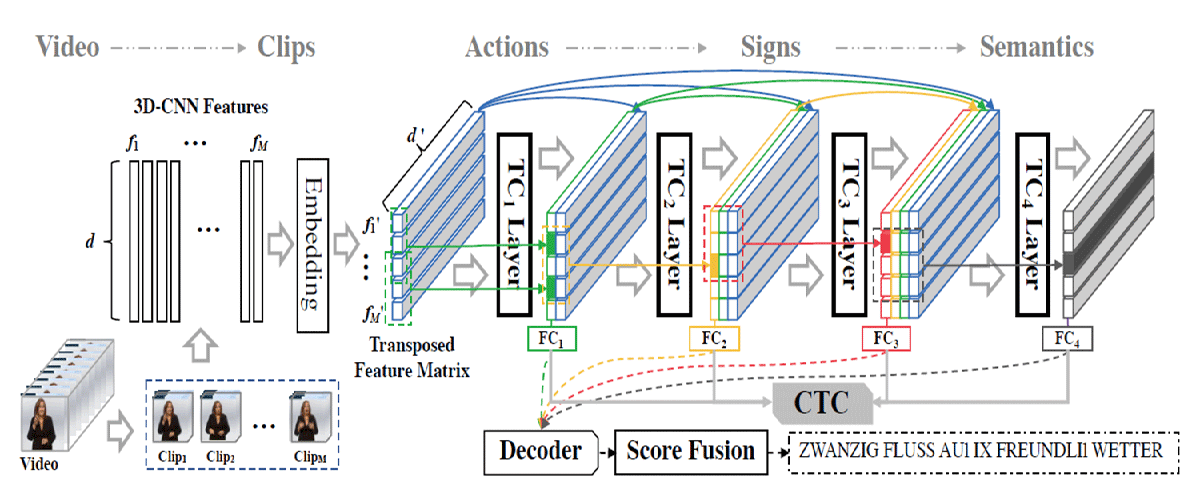
This part covers the researches related to sign language recognition, which focuses on continuous sign language translation (CSLT). In order to improve the recognition accuracy of isolated sign words, some early works design an adaptive hidden Markov model (HMM) framework. These methods can fully explore the intrinsic properties and complementary relationship among the hidden sign states. CSLT suffers from challenges presented by hybrid semantics learning among sequential variations of visual representations, sign linguistics, and textual grammars... [Details]
|
|
|
VQA & Visual Dialog
This part covers the researches related to visual dialog and video question answering. Visual dialog is a multi-round extension for visual question answering (VQA). The interactions between the image and multi-round question answer pairs are progressively changing, and the relationships among the objects in the image are influenced by the current question. Video question answering task aims... [Details]
|
|
|
Visual Captioning
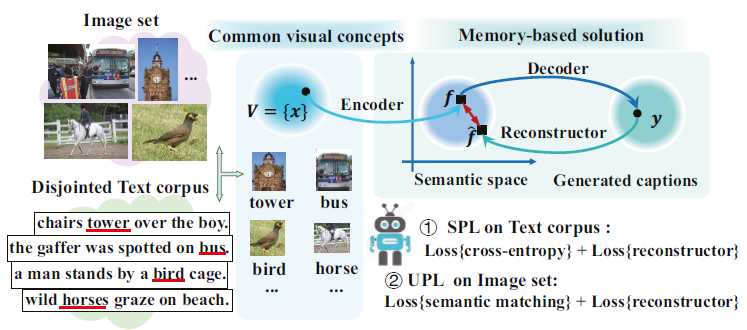
This part covers the researches related to visual captioning, including image captioning and video captioning. To releax the reliance on paired image-sentence data for image captioning training, unsupervised captioning with no annotations is explored through two-stage memory mechanisms. A GAN based method is proposed for exploring implicit semantic correlation between disjointed images and sentences through building a multimoda semantic aware space...[Details]
|
|
|
Visual Understanding
This part covers the researches related to visual understanding, which focuses on Crowd Counting, Visual Grounding, Video Grounding, and Temporal Action Localization (TAL). Crowd Counting is a task to count people in image. Different from object detection, Crowd Counting aims at recognizing arbitrarily sized targets in various situations including sparse and cluttering scenes at the same time...[Details]
|
Resources
Conferences Links: International Conferences on Machine Learning and Artificial Intelligence.
Members
Teacher
| Status |
Name |
Contact |
Research Interest |
| Professor |
Dan Guo |
guodan@hfut.edu.cn |
Video Analysis, Pattern Recognition |
| Lecturer |
Shengeng Tang |
tangsg@hfut.edu.cn |
Sign Language Translation & Production |
| Lecturer |
Jingyuan Xu |
xujingyuan@hfut.edu.cn |
Medical Image Processing, Posture Analysis |
Student
| Status |
Name |
Contact |
Research Interest |
| Ph.D student | Peipei Song | beta.songpp@gmail.com | Image Captioning, Emotional Video Captioning |
| Ph.D student | Kun Li | kunli.hfut@gmail.com | Visual Grouding, Crowd Counting |
| Ph.D student | Hui Wang | wanghui.hfut@gmail.com | Visual Dialogue, Video Question Answering |
| Ph.D student | Jinxing Zhou | zhoujxhfut@gmail.com | Audio-Visual Event Localization |
| Ph.D student | Qi Li | liqi_cs@stu.ahu.edu.cn | Remote Physiological Measurement |
| Ph.D student | Jing Zhang | hfutzhangjing@gmail.com | Cross-lingual Image Captioning |
| Ph.D student | Sheng Zhou | hzgn97@gmail.com | Text Visual Question Answering |
| Master student | Tianyi Lu | -- | Image Captioning |
| Master student | Wei Qian | qianwei.hfut@gmail.com | Remote Physiological Measurement |
| Master student | Fei Wang | -- | Video Magnification |
| Master student | Yan Zhang | -- | Micro-Action Localization |
| Master student | Zhentao Zheng | -- | Video Captioning |
| Master student | Guoliang Chen | -- | Emotion-Action Recognition |
| Master student | Zhangbin Li | -- | -- |
| Master student | Jiantao Nie | -- | -- |
| Master student | Jingjing Hu | -- | -- |
| Master student | Feiyang Liu | -- | -- |
| Master student | Jiahui Sun | -- | -- |
Alumni
| Status |
Name |
Now |
| Msc. 2020 | Chengxin Xiong | -- |
| Msc. 2020 | Xiankun Pei | Shanghai Pudong Development Bank |
| Msc. 2021 | Shihan Yan | Huishang Bank |
| Msc. 2021 | Yuling Gui | -- |
| Msc. 2021 | Fan Peng | Postal Savings Bank of China |
| Msc. 2022 | Shentao Yao | iFLYTEK |
| Msc. 2022 | Yichen Guo | -- |
Publications
Conference papers:
- Jinxing Zhou, Jianyuan Wang, Jiayi Zhang, Weixuan Sun, Jing Zhang, Stan Birchfield, Dan Guo, Meng Wang*, and Yiran Zhong*, "Audio−Visual Segmentation", European Conference on Computer Vision (ECCV), 2022. [Code]
- Shengeng Tang, Richang Hong*, Dan Guo*, and Meng Wang, "Gloss Semantic-Enhanced Network with Online Back-Translation for Sign Language Production", ACM International Conference on Multimedia (ACM MM), 2022.
- Hui Wang, Dan Guo*, Xiansheng Hua, and Meng Wang*, "Pairwise VLAD Interaction Network for Video Question Answering", ACM International Conference on Multimedia (ACM MM), 2021.
- Kun Li, Dan Guo*, and Meng Wang*, "Proposal-Free Video Grounding with Contextual Pyramid Network", AAAI Conference on Artificial Intelligence (AAAI), 2021.
- Dan Guo, Yang Wang*, Peipei Song*, and Meng Wang, "Recurrent Relational Memory Network for Unsupervised Image Captioning", International Joint Conference on Artificial Intelligence (IJCAI), 2020.
[Link][PDF][BibTeX]
- Dan Guo, Hui Wang*, Hanwang Zhang, Zhengjun Zha, and Meng Wang*, "Iterative Context-Aware Graph Inference for Visual Dialog", Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- Fan Peng, Kun Li, Xueliang Liu, and Dan Guo, "AOPNet: Anchor Offset Prediction Network for Temporal Action Proposal Generation", International Conference on Signal Processing, Communications and Computing (ICSPCC), 2020.
- Yuling Gui, Dan Guo, and Ye Zhao, "Semantic Enhanced Encoder-Decoder Network (SEN) for Video Captioning", Workshop on Multimedia for Accessible Human Computer Interfaces (MAHCI), 2019.
- Xiankun Pei, Dan Guo, and Ye Zhao, "Continuous Sign Language Recognition Based on Pseudo-supervised Learning", Workshop on Multimedia for Accessible Human Computer Interfaces (MAHCI), 2019.
- Peipei Song, Dan Guo, Haoran Xin, and Meng Wang, "Parallel Temporal Encoder For Sign Language Translation", IEEE International Conference on Image Processing (ICIP), 2019.
[Link][PDF][BibTeX]
- Dan Guo, Kun Li*, and Meng Wang, "DADNet:Dilated-Attention-Deformable ConvNet for Crowd Counting", ACM International Conference on Multimedia (ACM MM), 2019.
- Dan Guo, Shengeng Tang,and Meng Wang, "Connectionist Temporal Modeling of Video and Language:A Joint Model for Translation and Sign Labeling", International Joint Conference on Artificial Intelligence (IJCAI), 2019.
[Link][PDF][BibTeX]
- Dan Guo, Shuo Wang, Qi Tian, and Meng Wang, "Dense Temporal Convolution Network for Sign Language Translation", International Joint Conference on Artificial Intelligence (IJCAI), 2019.
[Link][PDF][BibTeX]
- Dan Guo, Hui Wang, and Meng Wang, "Dual Visual Attention Network for Visual Dialog", International Joint Conference on Artificial Intelligence (IJCAI), 2019.
- Shuo Wang, Dan Guo*, Wengang Zhou, Zhengjun Zha, and Meng Wang, "Connectionist Temporal Fusion for Sign Language Translation", International ACM International Conference on Multimedia (ACM MM), 2018.
[Link][PDF][BibTeX]
- Dan Guo, Wengang Zhou, Houqiang Li, and Meng Wang, "Hierarchical LSTM for Sign Language Translation", AAAI Conference on Artificial Intelligence (AAAI), 2018.
[Link][PDF][BibTeX]
- Dan Guo, Wengang Zhou, Houqiang Li, and Meng Wang, "Sign Language Recognition Based on Adaptive HMMs with Data Augmentation", IEEE International Conference on Image Processing (ICIP), 2016.
[Link][PDF][BibTeX]
Journal papers:
- Kun Li, Jiaxiu Li, Dan Guo*, Xun Yang*, and Meng Wang, "Transformer-Based Visual Grounding with Cross-Modality Interaction", ACM Transactions on Multimedia Computing Communications and Applications (TOMCCAP), 2023. [Link]
- Peipei Song, Dan Guo*, Jun Cheng, and Meng Wang*, "Contextual Attention Network for Emotional Video Captioning", IEEE Transactions on Multimedia (TMM), 2022.
- Peipei Song, Dan Guo*, Jinxing Zhou, Mingliang Xu, and Meng Wang*, "Memorial GAN with Joint Semantic Optimization for Unpaired Image Captioning", IEEE Transactions on Cybernetics (TCYB), 2022.
- Dan Guo, Hui Wang, and Meng Wang, "Context-Aware Graph Inference with Knowledge Distillation for Visual Dialog", IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2021.[Link]
- Shengeng Tang, Dan Guo*, Richang Hong*, and Meng Wang, "Graph-Based Multimodal Sequential Embedding for Sign Language Translation", IEEE Transactions on Multimedia (TMM), 2021.[Link][PDF][BibTeX]
- Dan Guo, Hui Wang, Shuhui Wang, and Meng Wang*, "Textual-Visual Reference-Aware Attention Network for Visual Dialog", IEEE Transactions on Image Processing (TIP), 2020.
- Dan Guo, Wengang Zhou*, Anyang Li, Houqiang Li, and Meng Wang*, "Hierarchical Recurrent Deep Fusion Using Adaptive Clip Summarization for Sign Language Translation", IEEE Transactions on Image Processing (TIP), 2020.
[Link][PDF][BibTeX]
- Shuo Wang, Dan Guo*, Xin Xu, Li Zhuo, and Meng Wang, "Cross-Modality Retrieval by Joint Correlation Learning", ACM Transactions on Multimedia Computing Communications and Applications (TOMCCAP), 2019.
[Link][PDF][BibTeX]
- Dan Guo, Wengang Zhou*, Houqiang Li*, and Meng Wang*, "Online Early-Late Fusion Based on Adaptive HMM for Sign Language Recognition", ACM Transactions on Multimedia Computing Communications and Applications (TOMCCAP), 2018.
[Link][PDF][BibTeX]
- Dan Guo, Shengeng Tang, Richang Hong, and Meng Wang, "Review of Sign Language Recognition, Translation and Generation", Computer Science, 2021.[Link][PDF][BibTeX]
- Chengxin Xiong, Dan Guo, and Xueliang Liu, "Temporal Proposal Optimization for Temporal Action Detection", Journal of Image and Graphics, 2020.[Link]
- Zhihong Lu, Dan Guo*, and Meng Wang, "Motion-compensated Frame Interpolation Based on Weighted Motion Estimation and Vector Segmentation", Acta Automatica Sinica, 2015.[Link]
Patents:
- 郭丹; 何梓贻; 倪友炜; 李坤; 徐梓鑫; 马嘉淇; 罗匡; 一种基于目标检测的碗碟清洗设备(实用新型), 2023-5-12, 中国, ZL202220873705.4.
- 郭丹; 唐申庚; 刘祥龙; 洪日昌; 汪萌; 一种基于图卷积的多模态融合手语识别系统及方法, 2023-3-14, 中国, ZL202010049714.7.
- 郭丹; 唐申庚; 刘祥龙; 汪萌; 一种基于多层次语义解析的手语翻译系统及方法, 2023-3-28, 中国, ZL202010103960.6.
- 赵烨; 胡晓斌; 胡珍珍; 刘学亮; 郭丹; 郭艳蓉; 吴乐; 一种基于注意力模型的视频摘要描述生成方法及装置, 2022-12-9, 中国, ZL202110565400.7.
- 郭丹; 宋培培; 刘祥龙; 汪萌; 基于递归记忆网络的无监督图像描述模型的生成方法, 2022-3-15, 中国, ZL202010049142.2.
- 郭丹; 宋培培; 刘祥龙; 汪萌; 基于数据自驱动的多阶特征动态融合手语翻译方法, 2022-3-15, 中国, ZL202010096391.7.
- 郭丹; 王辉; 汪萌; 一种基于上下文感知图神经网络的视觉对话生成方法, 2021-6-8, 中国, ZL201910881298.4.
- 郭丹; 李坤; 汪萌; 一种基于多尺度注意力机制的人群密度估计方法, 2021-3-9, 中国, ZL201910531606.0.
- 郭丹; 宋培培; 赵烨; 汪萌; 基于自适应隐马尔可夫的多特征融合手语识别方法, 2020-07-10, 中国, ZL201811131806.9.
- 郭丹; 汪萌; 周文罡; 李厚强; 李传青; 李安阳; 基于非对称多层LSTM的连续手语视频自动翻译方法, 2020-2-11, 中国, ZL201810027551.5.
- 郭丹; 王硕; 汪萌; 基于时域卷积网络与循环神经网络融合的手语视频翻译方法, 2019-10-18, 中国, ZL201811070290.1.
- 汪萌; 张鹿鸣; 郭丹; 一种基于多任务拓扑学习的航拍图像快速识别系统及其快速识别方法, 2018-2-6, 中国, ZL201510080478.4.
- 汪萌; 张鹿鸣; 郭丹; 田绪婷; 一种基于几何重构和语义融合的视点追踪方法, 2017-10-3, 中国, ZL201410733763.7.
- 郭丹; 胡学钢; 倪武; 吴信东; 一种基于最大流率路径优先的路网疏散规划方法, 2017-6-6, 中国, ZL201510451828.3.
- 汪萌; 杨勋; 洪日昌; 郭丹; 刘奕群; 孙茂松; 一种基于语义映射空间构建的图像检索方法, 2017-5-17, 中国, ZL201410393094.3.
- 汪萌; 洪日昌; 李炳南; 刘奕群; 郭丹; 刘学亮; 吴信东; 杨勋; 基于连续数标号子空间学习的检索重排序方法, 2017-2-22, 中国, ZL201410196946.X.
- 汪萌; 张鹿鸣; 郭丹; 刘奕群; 孙茂松; 鲁志红; 基于GPS信息视频的三维场景重建方法, 2017-2-22, 中国, ZL201410752454.4.
Software copyright:
- 鲁志红; 郭丹; 吴经纬; 刘菲; 张立缙; 田旭婷; 基于运动补偿的视频高清化播放软件 V1.0, 2014SR098634, 原始取得, 全部权利, 2014-07-16.
- 郭丹; 唐申庚; 陈颖男; 武梓龙; 文则涵; 刘泽宽; 基于关键点估计的人体姿态卡通化系统 V1.0, 2022SR0771364, 原始取得, 全部权利, 2022-06-16.
- 唐申庚; 黄滨; 郭丹; 谷纪豪; 盲人避障出行辅助系统 V1.0, 2023SR0517944, 原始取得, 全部权利, 2023-05-05.
© VUT-HFUT 2021 Last updated on Mar. 28, 2023